ApplicationXtender Full Text Search (Xplore) Module
ApplicationXtender (AX) Full Text Search (Xplore) expedites finding records in AX. AX Full Text Search/Xplore allows users to combine keywords and full-text searches to return the most precise search results with just a single query.
Benefits
AX Full Text Search provides the ability to navigate files and content quickly, to expedite the information discovery process and reduce the risks associated with managing vast volumes of unstructured information. With AX Full Text Search, knowledge workers can combine keywords and full-text searches to return the most precise search results with just a single query.
ApplicationXtender Full Text Search (Xplore) delivers:
Precise search results
Advanced search functions
Support for hundreds of file formats
Role-based information access
Methodology
There are two methods of retrieving keyword or phrase matches from a PDF document in AX: Text Over Image or Text File Match
The result you get is dependent on the presence of data attached to the document prior to uploading it to AX.
Text Over File
Situation
When a user does a Full Text Search the image of the record appears with the first search word Highlighted. It prompts the user with the number of matches found and what pages the first hit is located on. This is the more sought-after solution as it allows to see their search matches directly on the image.
How to achieve
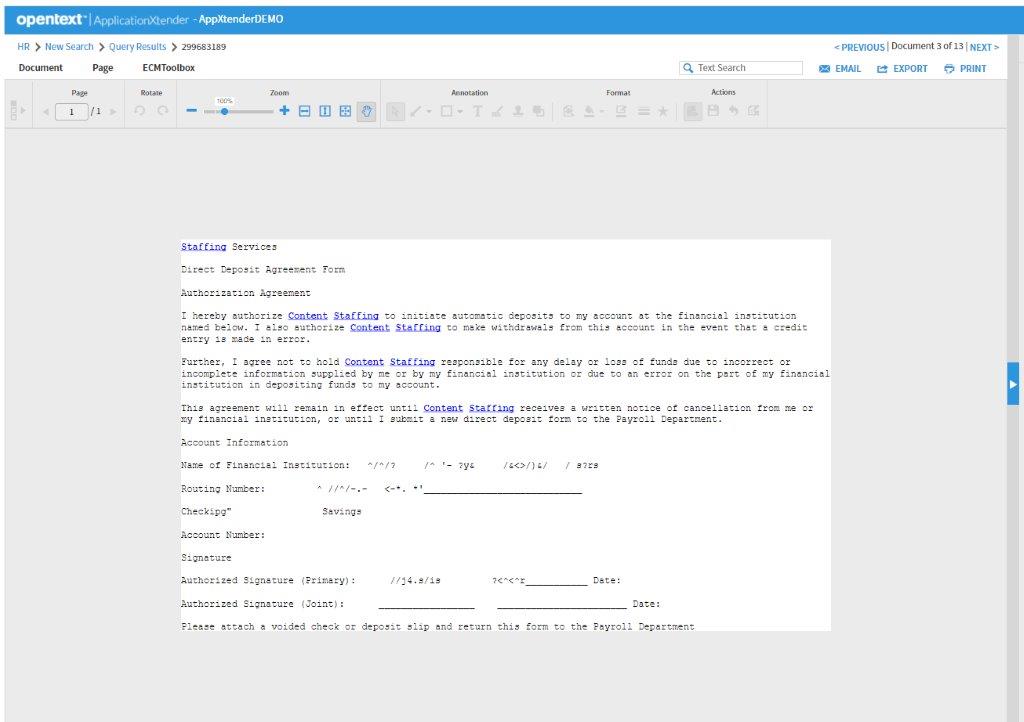
The PDF must undergo an OCR or data recognition engine process prior to import. Typically, this can work when a document is processed with any OCR engine or even by using the “Text Recognition” feature found in Acrobat/ Acrobat Pro.
How to test
Text File Match
Situation
When a user does a Full Text Search AX redirects to a text file of the OCR data and highlights the keyword or phrase entered. This text file only contains OCR data and will not display the image associated with this data. While viewing the text file, the user can alternate between the image view and the text view.
How to achieve

This occurs when the PDF is imported into AX with no pre-existing OCR data AND undergoes AX’s OCR engine. AX’s OCR engine will only produce a text based reference of the data despite the document being in a native PDF format.
How to test
* Note – the OCR engine must be enabled for the application for documents to submit to the engine. If not, the document will not be OCR’d by AX and no results will return when searched for.
If enabled, documents are automatically submitted to the engine when saved to the application.
AX has an OCR and Full-Text queue that can be monitored in the Admin console.
Processing Existing Records
Many clients want to run Xplore on their existing records along with newly arrived records. The best practice is to set-up a separate server to process the records. Each project will vary based on records and servers. Below are statistics from a past project where 1,498,317 records were processed with images in PDF and TIFF format:


** Note: Additional Servers can be utilized to reduce the amount of time needed to complete the process
Contact Us
Fill out the form below to get in touch with us. We’ll get back to you right away.
CASO has helped us get over the ‘change hump.’ Not only can we get things done quicker with the electronic workflow implemented by CASO, but we can also now measure productivity for staffing models and customer satisfaction.